
Census 2.0
This post was originally posted on the Cevo Australia website
In light of the #CensusFail the ABS delivered to us on Tuesday night, I thought I’d put a blog post where my mouth is and suggest an architecture I feel would have delivered had Cevo been involved in the creation of this years’ Census application.
Having not already completed the Census, I’m not 100% sure of what the official requirements are, but I will take a crack at designing a solution from a guesstimate of what they would need.
Requirements:
- Ability to validate the ‘unique code’ sent to each household.
- Ensure that the same unique code cannot submit the form multiple times
- Provide multiple pages of forms with:
- many translations
- explanatory text
- options for conditional field selection controlling validation rules on following actions.
- Confirmation of successful submission
- Ability to segregate the submission of different parts of the form to different datastores
And most importantly
- Handle over 5 million users accessing the service within a 1-hour window of time.
Disclaimer: I’m sure the actual requirements are more comprehensive and have some gotchas in this, but the thought exercise was completed on a Friday night, watching the footy with a beer in my hand..
I jokingly suggested during the week that a form on top of a google spreadsheet would have been a solid solution, and there are aspects of this that actually do make sense.
Design considerations
Deliver as much content as possible from a CDN
One of the biggest issues (if not the biggest) with the existing Census setup was the inability to cope with the demand requirements of 5 million or more households having dinner and then all firing up their browsers within 45 minutes of each other.
To reduce the burden on the central control points, ensure the application is delivered to customers from multiple edge locations. Even if one of these points gets swamped, the overall network will be able to respond to the vast majority of service requests. In addition, most CDNs provide a level of DDoS-resilience out of the box, with Web Application Firewall (WAF) capability also coming as a standard optional extra.
Limit the number of stateful requests
In any large scale system, state is your enemy. It means that you have to both persist and read that state from somewhere to keep all the parts in sync (or worse, force each client to talk to a single server). Your state persistence component is now a single point of failure, which can be addressed by sprinkling in High Availability and other levels of complexity.
In this solution, the need for state can be simplified into 2 key events. An initial event that validates the unique code is truly unique and valid, and the final submission of all the Census results.
Select a solution that provides horizontal scaleability
Even with offloading content to a CDN, and reducing the state, 5 million requests to any solution within a 15 minute window will be tough unless you have architected to support it. Doing some simple maths, that’s (5,000,000/(15*60)) which is a little over 5,500 requests/second. For many large websites, that’s not even a tickle, but for an unprepared site it spells meltdown.
Ensuring that the key processing units in the system are able to be run in parallel, and the technology chosen to deliver this processing can quickly and easily be turned on (And off) to add (and then remove) parallel streams as needed allows us to respond transparently to the level of demand without incurring unnecessary “spare” capacity cost.
Create a write-only data store to isolate risk of data breach
The primary purpose of this system was to collect the data, it doesn’t need to do anything complex with it, doesn’t need to put it into any transactional system, it only needs to validate the content is complete, and format of any key items is correct and record it. It does need to be stored securely, so adding encryption to data at rest is standard.
Processing to move this data into a transactional system, create reports or analytics, can be done offline, in longer term slower processing approaches.
Make change to the system easy and consistent
It’s also important to know that you won’t get it right and, when playing at this scale, it’s important that if things do go wrong you can easily and confidently fix the running system.
I’ve seen lots of comments this week about how companies like Facebook and Twitter can handle billions of users, not just a few million like on Census night. But remember they have had years to perfect their systems, and the only way they handle this scale was through the ability to evolve.
The Census was a big bang event, and in spite of the attempts to load-test beforehand, real-world load often looks different from generated load. Presumably a large number of assumptions had to be made, and often assumptions are only proven incorrect in production.
Being able to make changes to running systems in the heat of the battle, with confidence that the changes you are making are not making things worse should be a key component in any application design.
Solution design
At this scale, you need a service provider who can provide internet scale services, has been battle tested and has a proven track record of handling massive scale applications.
Over the past few year AWS have demonstrated multiple times that they fit this bill and, with the introduction of a series of new services that increase flexibilty and reduce management overhead, present as an ideal platform on which to build a Census 2.0 application.
Overview
By using a “serverless” architecture, the application sits on a platform that is built for scale, and requires the application developers to bear in mind the management and impact of state.
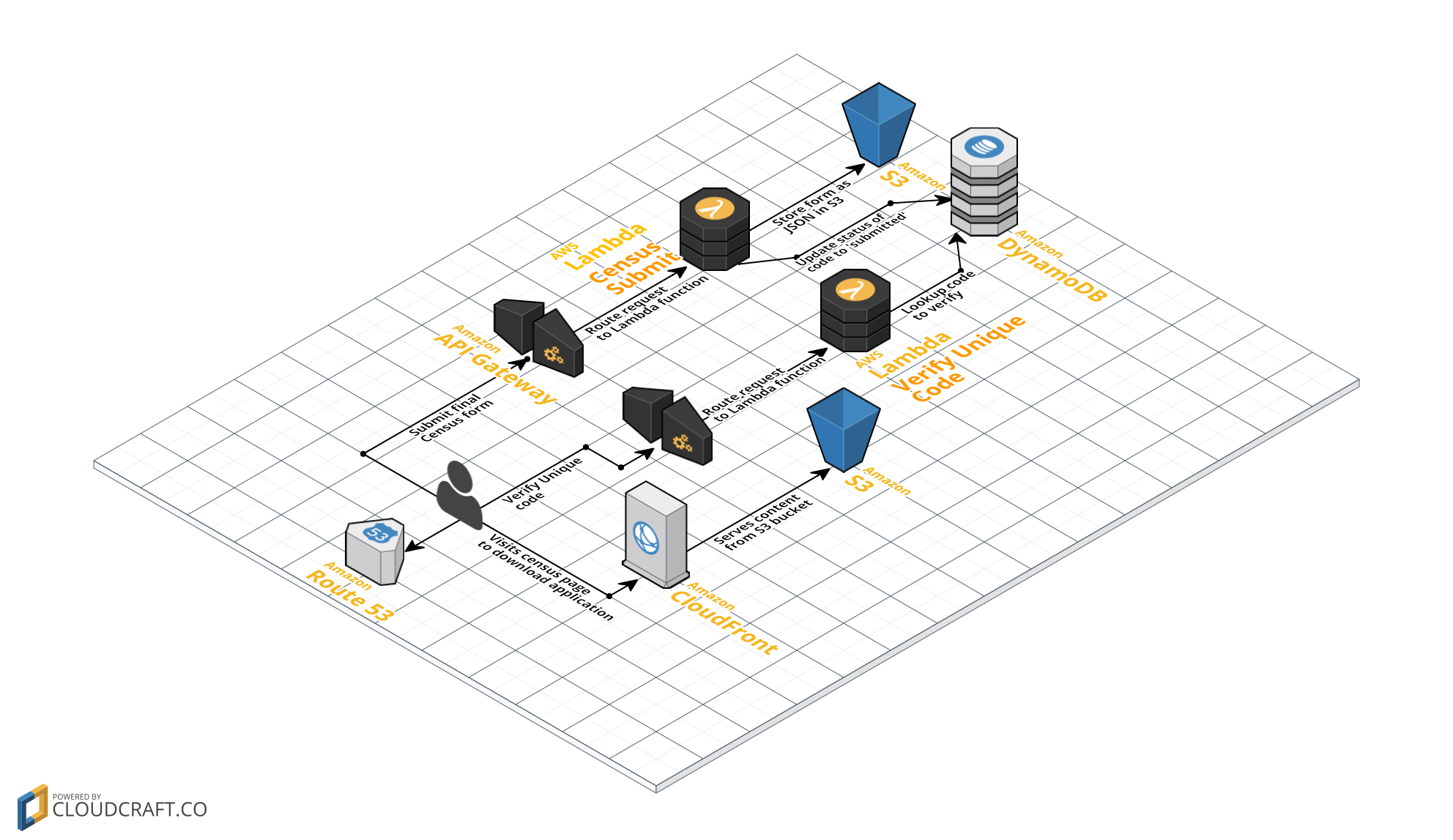
Front End
Let’s start by developing the Census form in a manner that sees the bulk of the logic and content delivered to the browser as a set of static HTML, CSS and JavaScript. There are a number of JavaScript based UI toolkits, so I’ll leave it to you to pick your favourite.
Requirements for the front end are that all the static content (javascript, images, and content) can be delivered from a CDN to the browser without any need to run any server-side (website-end) processes. This removes the need for high-end webservers just to deliver the basic pages to the browser.
Static Content Delivery and CDN
To deliver this content to customers, use the CDN combination of S3 and CloudFront to provide multiple Edge Locations in both Melbourne and Sydney.
Security
Importantly, both API Gateway and S3 support the use of SSL/TLS certificates to ensure security around the delivery of the application to the customers, as well as the delivery of content to the submission backend.
Because Census data is the canonical example of Sensitive PII, all data must be strongly encrypted in transit (via HTTPS) and while at rest.
Validation of Unique Census Code
By using the built in security features of the AWS platform, the architecture could be positioned with the following constraints:
- S3 bucket that stores the application content independent from the Census storage bucket.
- Lambda function that checks unique code can only read from the DynamoDB.
- Lambda function that accepts the form submission can update the DynamoDB, and only write to the S3 bucket, ensuring no permission to list or read from the bucket.
- All traffic delivered to and from client is encrypted with SSL/TLS.
I assume the list of unique codes already existed (after all, the ABS sent out letters to each address with an unique code pre-assigned), so let’s pre-populate a high bandwidth, low latency data store (DynamoDB) to enable quick lookup and validation.
When a form is successfully submitted, a flag could be recorded against the DynamoDB record to lock this key from re-use; this has no relationship to the Census data itself, and so meets requirements of separation of data.
Form Submission and Validation
With the majority of heavy lifting being done on the client side through the use of JavaScript based UI frameworks, the requirements on form submission can be greatly simplified.
By using API Gateway backed onto an AWS Lambda function, the complexity of the system under control is greatly simplified. One key feature of the Lambda platform is its ability to scale-out automatically and transparently to execute Lambda functions in parallel if required..
This function would not need to access any data store for processing as the client side JavaScript application would be able to submit the entire packet in one post.
It would only need to validate a relatively small data packet for completeness and data validity, on failure return sufficient error messages for the client side application to give feedback to the user.
If the submitted data was valid, it need not access any database, but simply upload this JSON element to an S3 bucket configured for write only access. The Lambda function only keeps the data in-memory long enough to validate it, before writing to the encrypted S3 storage. Amazon’s KMS (Key Management Service) permits us to provide strong controls over who can access the encrypted data once it’s stored.
Conclusion
I don’t want to comment on the current solution, its vendors or the approach taken by the ABS, but will conclude by saying that with:
- the recent emergence of Serverless application architectures;
- the continued maturity of automated delivery solutions and;
- the commoditisation of infrastructure as a service being achieved by Cloud Computing suppliers
the possible options to deliver solutions have drastically increased.
Don’t write off a lot of this new technology and the approaches behind them, while the tools and frameworks in this space might only be young, their potential applications have only begun to be explored.
Caveats
Yes, there are real-world requirements that this simple overview doesn’t cover; in-progress saving of forms, clients that cannot (or will not) use Javascript, and probably more. This is a thought exercise rather than a full-fledged system design – however, if you’d like a full-fledged system design, or assistance with implementing your own, please contact us!.
Also; we know most of what’s wrong with this back-of-the-envelope design. Would you like to help improve it? For real clients? Check out our careers page


Comments